简单排序 冒泡排序 排序原理:
1、比较相邻的元素,如果前一个元素比后一个元素大,就交换这两个元素的位置
2、对每一对元素都这样处理,最后的出来的结构就是排序完成的结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class BubbleTest { public static void main (String[] args) { Integer[] arr = {4 ,5 ,6 ,3 ,2 ,1 }; Bubble.sort(arr); } } public class Bubble { public static void sort (Comparable[] a) { for (int i=a.length-1 ;i>0 ;i--){ for (int j=0 ;j<i;j++){ if (greater(a[j],a[j+1 ])){ exch(a,j,j+1 ); } } } } private static boolean greater (Comparable v, Comparable w) { return v.compareTo(w)>0 ; } private static void exch (Comparable[] a, int i, int j) { Comparable temp; temp = a[i]; a[i] = a[j]; a[j] = temp; } }
冒泡排序时间复杂度分析:O(n^2)
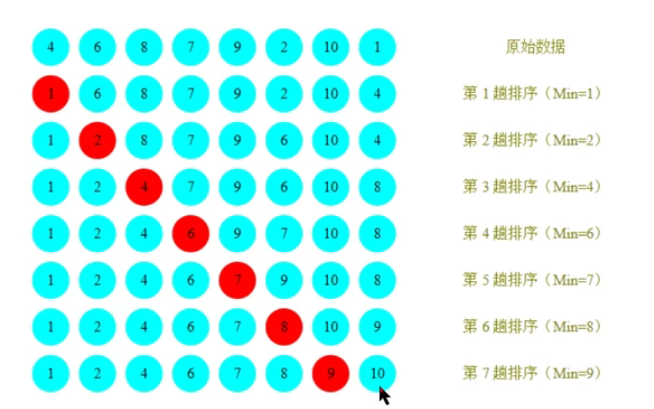
选择排序 排序原理:
1、每一次遍历过程中,都假定第一个索引处的元素是最小值,然后依次和其他索引处的值进行比较,直到找到本次遍历最小值
2、交换第一个索引处和最小值所在的索引处的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public class Selection { public static void sort (Comparable[] a) { for (int i=0 ; i<=a.length-2 ; i++){ int minIndex = i; for (int j=i+1 ; j<a.length; j++){ if (greater(a[minIndex],a[j])){ minIndex = j; } } exch(a,i,minIndex); } } private static boolean greater (Comparable v, Comparable w) { return v.compareTo(w)>0 ; } private static void exch (Comparable[] a, int i, int j) { Comparable temp; temp = a[i]; a[i] = a[j]; a[j] = temp; } }
选择排序时间复杂度分析:O(n^2)
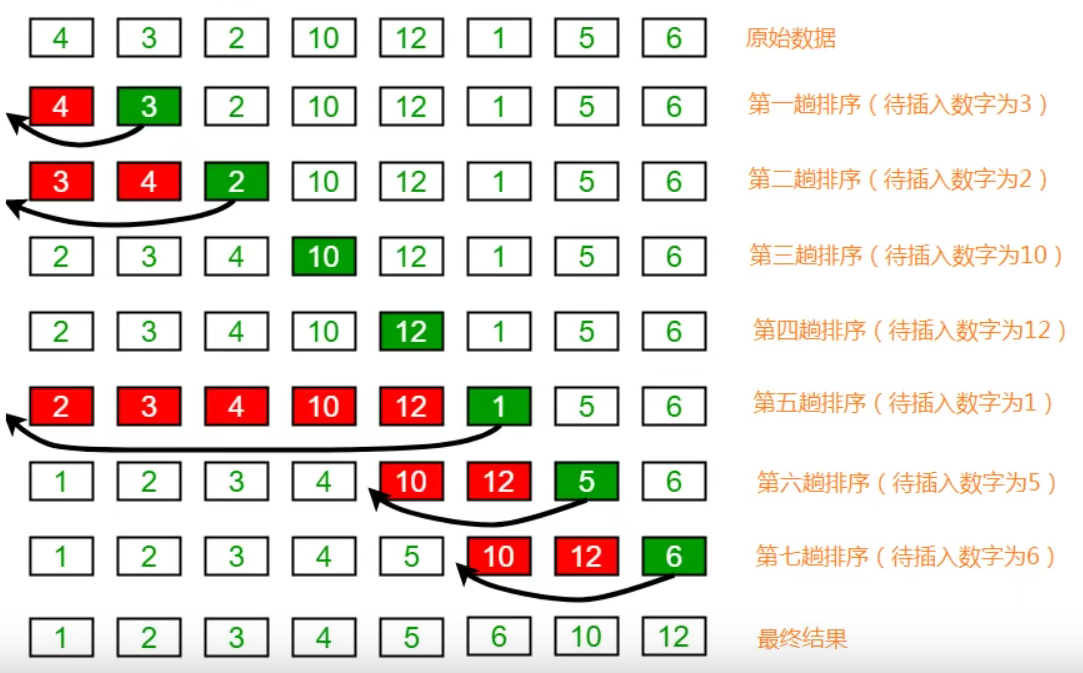
插入排序 排序原理:
1、将所有元素分为已排序和未排序
2、将未排序数组的第一个元素向已排序数组中插入
3、倒叙遍历已排序数组,找到小于或等于插入元素的元素,并将插入元素放到这个位置,其余元素向后移动一位
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class Insertion { public static void sort (Comparable[] a) { for (int i = 1 ; i<a.length; i++){ for (int j=i; j>0 ; j--){ if (greater(a[j-1 ],a[j])){ exch(a,j-1 ,j); }else { break ; } } } } private static boolean greater (Comparable v, Comparable w) { return v.compareTo(w)>0 ; } private static void exch (Comparable[] a, int i, int j) { Comparable temp; temp = a[i]; a[i] = a[j]; a[j] = temp; } }
**插入排序时间复杂度分析:O(n^2) **
(其本质跟冒泡排序相似)
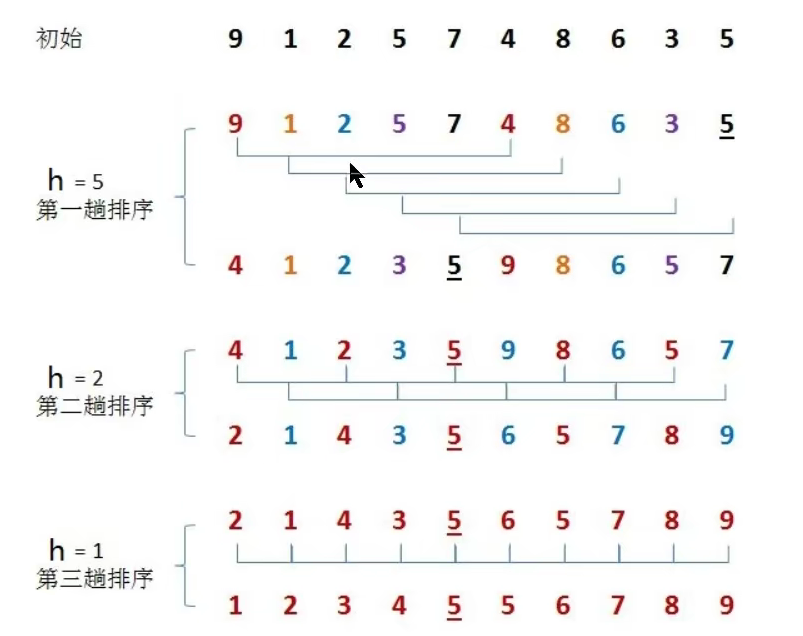
高级排序 希尔排序 希尔排序是插入排序的一种,又叫”缩小增量排序“ ,希尔排序的增量没有固定的规则
希尔排序的时间的时间复杂度为
,希尔排序时间复杂度的下界是n*log2n。希尔排序没有快速排序算法快 O(n(logn)),因此中等大小规模表现良好,对规模非常大的数据排序不是最优选择。但是比
复杂度的算法快得多。
专家们提倡,几乎任何排序工作在开始时都可以用希尔排序,若在实际使用中证明它不够快,再改成快速排序这样更高级的排序算法
排序原理:
1、选定一个增量h,按照增量h作为数据分组的依据,对数据进行分组
2、对分好组的每一组数据完成插入排序
3、减小增长量,最小减一,重复第二步
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public class Shell { public static void sort (Comparable[] a) { int h=1 ; while (h<a.length/2 ){ h=2 *h+1 ; } while (h>=1 ){ for (int i=h; i<a.length; i++){ for (int j=i; j>=h; j-=h){ if (greater(a[j-1 ],a[j])){ exch(a,j-1 ,j); }else { break ; } } } h=h/2 ; } } private static boolean greater (Comparable v, Comparable w) { return v.compareTo(w)>0 ; } private static void exch (Comparable[] a, int i, int j) { Comparable temp; temp = a[i]; a[i] = a[j]; a[j] = temp; } }
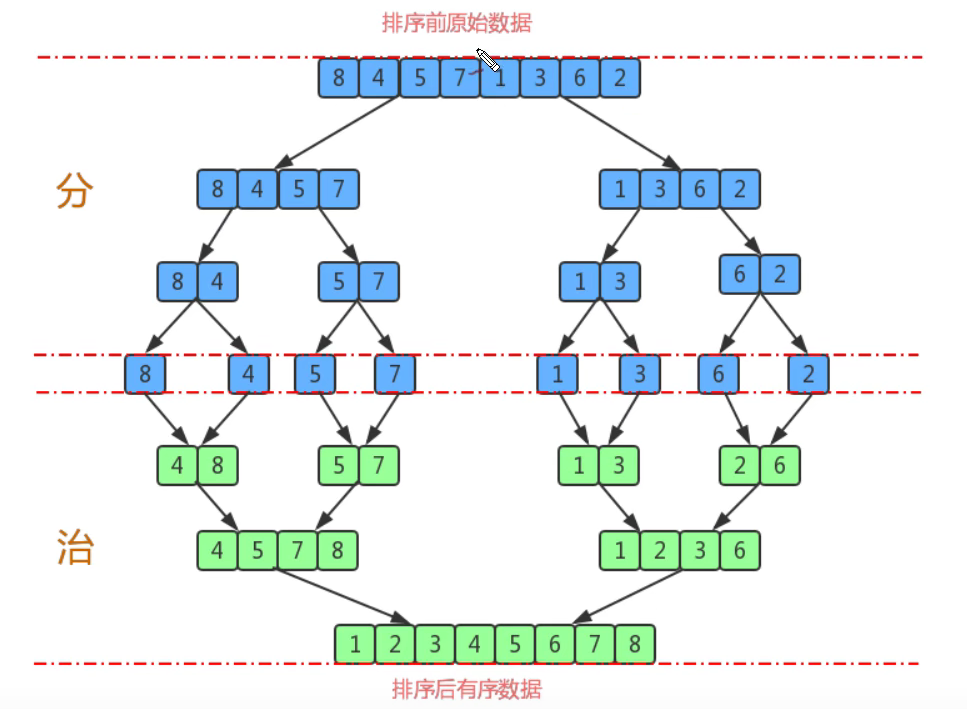
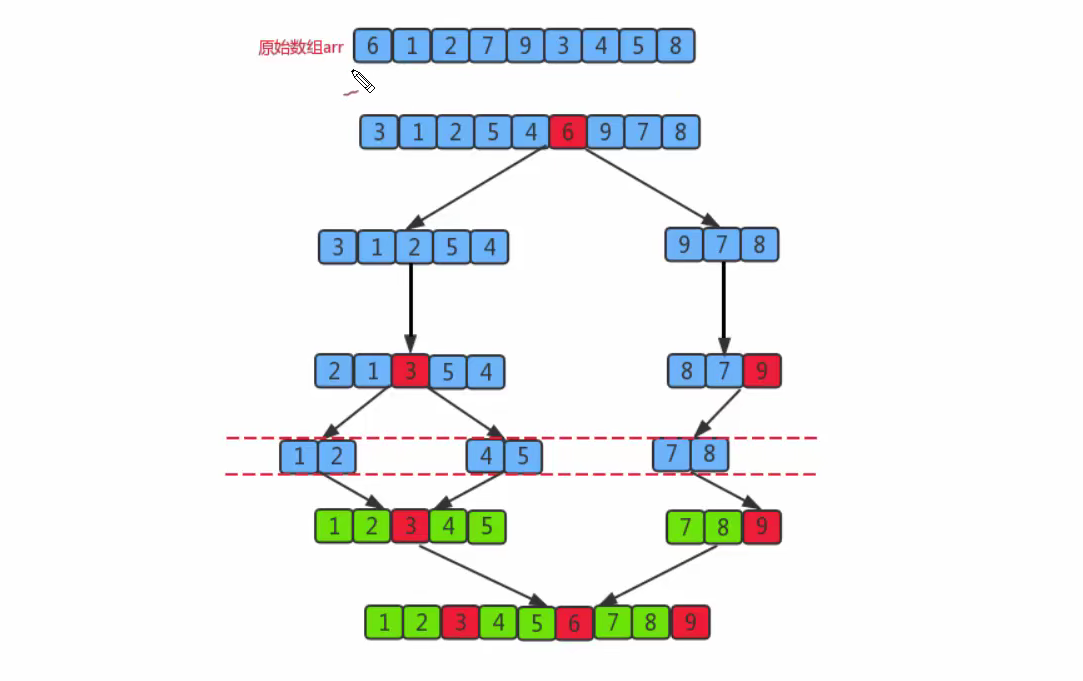
归并排序 归并排序体现的是分而治之的思想
排序原理:
1、尽可能的将一组数据拆分成两个元素相等的子组,并对每一个子组继续拆分,直到拆分后的每个子组的元素个数为1
2、不断将相邻的两个子组进行合并成一个有序的大组,直到只有一个组为止
使用辅助数组,对两个子组进行排序,排序方式与合并两个有序链表的方式类似
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 public class Merge { private static Comparable[] assist; public static void sort (Comparable[] a) { assist = new Comparable [a.length]; int lo = 0 ; int hi = a.length-1 ; sort(a,lo,hi); } private static void sort (Comparable[] a, int lo, int hi) { if (hi<=lo){ return ; } int mid = lo+(hi-lo)/2 ; sort(a,lo,mid); sort(a,mid+1 ,hi); merge(a,lo,mid,hi); } private static void merge (Comparable[] a, int lo, int mid, int hi) { int i = lo; int p1 = lo; int p2 = mid+1 ; while (p1<=mid && p2<hi){ if (less(a[p1],a[p2])){ assist[i++] = a[p1++]; }else { assist[i++] = a[p2++]; } } while (p1<=mid){ assist[i++] = a[p1++]; } while (p2<=hi){ assist[i++] = a[p2++]; } for (int index=lo; index<=hi; index++){ a[index] = assist[index]; } } private static boolean less (Comparable v, Comparable w) { return v.compareTo(w)<0 ; } private static void exch (Comparable[] a, int i, int j) { Comparable temp; temp = a[i]; a[i] = a[j]; a[j] = temp; } }
归并排序的时间复杂度分析:O(n logn)
快速排序 排序原理:
1、首先设定一个分界值,通过该分界值将数组分成左右两部分
2、将大于或等于分界值的放到数组右边,小于分界值的放到数值左边
3、重复操作分界值左右两边的元素,最终就得到排序好的数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 public class Quick { public static void sort (Comparable[] a) { int lo = 0 ; int hi = a.length-1 ; sort(a,lo,hi); } private static void sort (Comparable[] a, int lo, int hi) { if (lo>=hi){ return ; } int partition = partition(a,lo,hi); sort(a,lo,partition-1 ); sort(a,partition+1 ,hi); } private static int partition (Comparable[] a, int lo, int hi) { Comparable key = a[lo]; int left = lo; int right = hi+1 ; while (true ){ while (less(key,a[--right])){ if (right == lo){ break ; } } while (less(a[++left],key)){ if (left == hi){ break ; } } if (left>=right){ break ; }else { exch(a,left,right); } } exch(a,lo,right); return right; } private static boolean less (Comparable v, Comparable w) { return v.compareTo(w)<0 ; } private static void exch (Comparable[] a, int i, int j) { Comparable temp; temp = a[i]; a[i] = a[j]; a[j] = temp; } }
快速排序的时间复杂度分析:最优情况:O(nlogn) 最坏情况:O(n^2)
归并排序和快速排序的区别:
归并排序将数组分成两个子数组分别排序,并将有序的子数组归并,从而将整个数组排序
快速排序的方式是当两个数组都有序时,整个数组就有序了
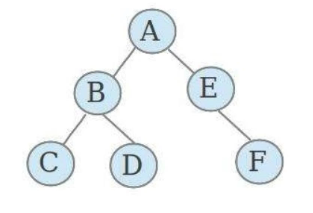
树 树的定义:
树是由n个有限结点组成一个具有层次关系的集合。它看起来像一颗倒挂的树
树的特点:
1、每个结点有零个或多个子结点
2、没有父节点的结点为根结点
3、每一个非根节点只有一个父结点
4、每个结点及其后代结点整体上可以看作是一个棵树,称为当前结点的父节点的一个子树
结点的度:
一个结点含有的子树的个数称为该结点的度
叶结点:
度为0的结点也称为叶结点
树的度:
树中所有结点的度的最大值
树的深度:
树中结点的最大层次
二叉树 二叉树就是度不超过2的树
满二叉树:
一个二叉树,如果每一个层的结点树都达到最大值 ,则这个二叉树就是满二叉树
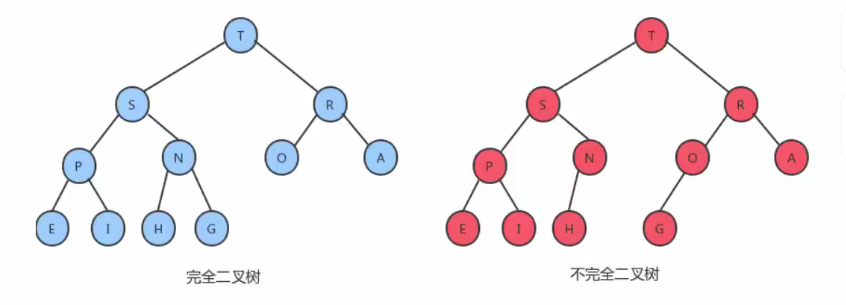
完全二叉树:
叶结点只能出现在最下层和次下层
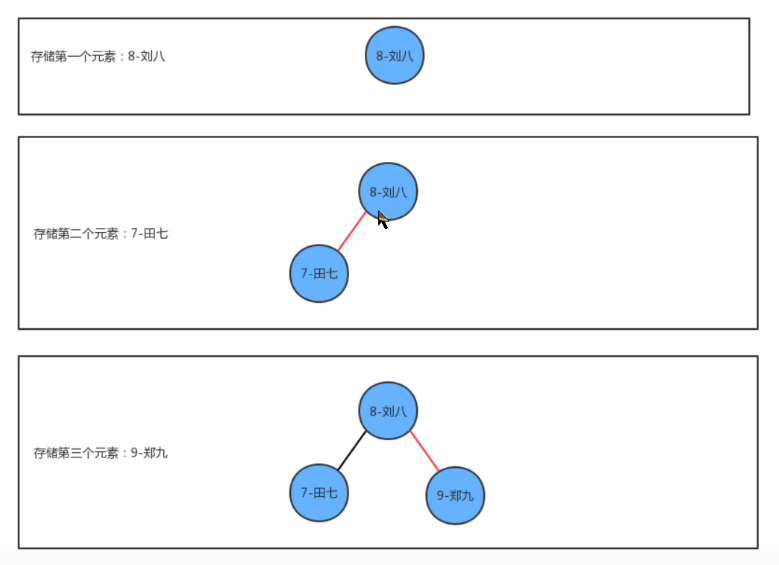
二叉查找树的创建 插入方法put的实现思想:
1、如果当树中没有任何一个结点,则直接把新结点作为根结点
2、如果当前树不为空,则从根结点开始
如果新结点的key小于当前结点的key,则继续找当前结点的左子结点
如果新结点的key大于当前结点的key,则继续找当前结点的右子结点
如果新结点的key等于当前结点的key,则树中已经存在这样的结点,替换该结点的value值即可
查询方法get实现思想:
从根结点开始
如果要查询的key小于当前结点的key,则继续找当前结点的左子结点
如果要查询的key大于当前结点的key,则继续找当前结点的右子结点
如果要查询的key等于当前结点的key,则返回当前结点的value值
删除方法delete实现思想:
代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 public class BinaryTree <Key extends Comparable <Key>,Value>{ private Node root; private int N; public void put (Key key, Value value) { root = put(root,key,value); } public Node put (Node x, Key key, Value value) { if (x == null ){ N++; return new Node (key,value,null ,null ); } int cmp = key.compareTo((Key) x.key); if (cmp>0 ){ x.right = put(x.right,key,value); }else if (cmp<0 ){ x.left = put(x.left,key,value); }else { x.value = value; } return x; } public Value get (Key key) { return get(root,key); } private Value get (Node x, Key key) { if (x == null ){ return null ; } int cmp = key.compareTo((Key) x.key); if (cmp>0 ){ return get(x.right,key); }else if (cmp<0 ){ return get(x.left,key); }else { return (Value) x.value; } } public void delete (Key key) { delete(root,key); } public Node delete (Node x, Key key) { if (x == null ){ return null ; } int cmp = key.compareTo((Key) x.key); if (cmp>0 ){ x.right = delete(x.right,key); }else if (cmp<0 ){ x.left = delete(x.left,key); }else { if (x.right == null ){ return x.left; } if (x.left == null ){ return x.right; } Node minNode = x.right; while (minNode.left != null ){ minNode = minNode.left; } Node n = x.right; while (n.left != null ){ if (n.left.left == null ){ n.left = null ; }else { n = n.left; } } minNode.left = x.left; minNode.right = x.right; x = minNode; N--; } return x; } public int size () { return N; } }
二叉查找树中最小的键 1 2 3 4 5 6 7 8 9 10 11 12 public Key min () { return (Key) min(root).key; } public Node min (Node x) { if (x.left != null ){ return min(x.left); }else { return x; } }
二叉查找树中最大的键 1 2 3 4 5 6 7 8 9 10 11 12 public Key max () { return (Key) min(root).key; } public Node max (Node x) { if (x.right != null ){ return max(x.right); }else { return x; } }
二叉树的遍历 很多情况下,我们需要遍历树,由于树状结构和线性结构不一样,它没有办法从头开始依次向后遍历,所以存在如何遍历,也就是按照什么样的搜索路径 进行遍历的问题
我们可以把二叉树的低级遍历方式 分为以下三种方式:
1、先序遍历:
先访问根结点,再访问左子树,最后访问右子树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public List<Key> preErgodic () { List<Key> keys = new ArrayList <>(); preErgodic(root,keys); return keys; } private void preErgodic (Node x, List<Key> keys) { if (x == null ){ return ; } keys.add((Key) x.key); if (x.left != null ){ preErgodic(x.left,keys); } if (x.right != null ){ preErgodic(x.right,keys); } }
2、中序遍历:
先访问左子树,再访问根结点,最后访问右子树
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public List<Key> midErgodic () { List<Key> keys = new ArrayList <>(); midErgodic(root,keys); return keys; } private void midErgodic (Node x, List<Key> keys) { if (x == null ){ return ; } if (x.left != null ){ midErgodic(x.left,keys); } keys.add((Key) x.key); if (x.right != null ){ midErgodic(x.right,keys); } }
3、后序遍历:
先访问左子树,再访问右子树,最后访问根结点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public List<Key> afterErgodic () { List<Key> keys = new ArrayList <>(); afterErgodic(root,keys); return keys; } private void afterErgodic (Node x, List<Key> keys) { if (x == null ){ return ; } if (x.left != null ){ afterErgodic(x.left,keys); } if (x.right != null ){ afterErgodic(x.right,keys); } keys.add((Key) x.key); }
高级遍历方式:层序遍历
实现步骤:
创建队列,存储每一层的结点
使用循环从队列弹出一个结点
此处使用ArrayList来代替队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public List<Key> layerErgodic () { List<Key> keys = new ArrayList <>(); List<Node> nodes = new ArrayList <>(); nodes.add(root); while (!nodes.isEmpty()){ Node node = nodes.get(0 ); nodes.remove(0 ); keys.add((Key) node.key); if (node.left != null ){ nodes.add(node.left); } if (node.right != null ){ nodes.add(node.right); } } return keys; }
二叉树的最大深度问题 给定一颗树,计算树的最大深度(树的根结点到最远叶子结点的最长路径上的结点数)
实现步骤:
如果根结点为空,则最大深度为0
计算左子树的最大深度
计算右子树的最大深度
当前树的最大深度 = 左子树的最大深度和右子树的最大深度中的较大者 + 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public int maxDepth (Node x) { if (x == null ){ return 0 ; } int max = 0 ; int maxL = 0 ; int maxR = 0 ; if (x.left != null ){ maxL = maxDepth(x.left); } if (x.right != null ){ maxR = maxDepth(x.right); } max = maxL>maxR?maxL+1 :maxR+1 ; return max; }
堆 堆的定义 堆是计算机科学中一类特殊的数据结构的统称,堆通常可以被看做是一颗完全二叉树的数组对象
堆的特性:
1、它是完全二叉树,除了树的最后一层结点不需要是满的,其它的每一层从左到右都是满的,如果最后一层不满,则要求左满右不满
2、它通常是用数组来实现
具体方法就是将二叉树的结点按照层级顺序放入数组中
如果一个结点为位置为k,则它的父结点则为【k/2】,而它的两个子结点的位置则分别为【2k】和【2k+1】
3、每个结点都大于等于它的两个子结点。虽然这样规定,但是子结点的位置顺序并没有规定
堆的实现 insert插入方法的实现
由于堆的定义是父结点大于两个子结点,且堆是由数组实现,所以在我们插入一个比父结点大的元素时就需要从插入元素的位置不断跟其父结点比较,如果父结点比子结点小则交换位置
delMax删除最大元素方法的实现
由于堆的定义,其根结点就是最大值,所以将其删除后将会导致堆的顺序变化,从而导致堆不符合定义;所以这时我们可以暂时把堆中最后一个元素拿出,并放到索引1处,然后使用下沉算法使堆有序
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 public class Heap <T extends Comparable > { private T[] items; private int N; public Heap (int capacity) { this .items = (T[])new Comparable [capacity+1 ]; this .N = 0 ; } private boolean less (int i, int j) { return items[i].compareTo(items[j])<0 ; } private void exch (int i, int j) { T temp = items[i]; items[i] = items[j]; items[j] = temp; } public T delMax () { T max = items[1 ]; exch(1 ,N); items[N] = null ; N--; sink(1 ); return max; } public void insert (T t) { items[++N] = t; swim(N); } private void swim (int k) { while (k>1 ){ if (less(k/2 ,k)){ exch(k/2 ,k); } k=k/2 ; } } private void sink (int k) { while (2 *k <= N){ int max; if (2 *k+1 < N){ if (less(2 *k,2 *k+1 )){ max = 2 *k+1 ; }else { max = 2 *k; } }else { max = 2 *k; } if (!less(k,max)){ break ; } exch(k,max); k = max; } } }
堆排序 实现步骤:
1、构造堆
2、得到堆顶元素
3、交换堆顶元素和数组中的最后一个元素,此时所有元素中的最大元素已经放到合适的位置
4、对堆进行调整,重新让除了最后一个元素的剩余元素中的最大值放到堆顶
5、重复2~4步骤,直到堆中剩余一个元素为止
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 public class HeapSort { public static void sort (Comparable[] source) { Comparable[] heap = new Comparable [source.length+1 ]; createHeap(source,heap); int N = heap.length-1 ; while (N != 1 ){ exch(heap,1 ,N); N--; sink(heap,1 ,N); } System.arraycopy(heap,1 ,source,0 ,source.length); } private static void createHeap (Comparable[] source, Comparable[] heap) { System.arraycopy(source,0 ,heap,1 ,source.length); for (int i = (heap.length)/2 ; i>0 ; i--){ sink(heap,i,heap.length-1 ); } } private static boolean less (Comparable[] heap, int i, int j) { return heap[i].compareTo(heap[j]) < 0 ; } private static void exch (Comparable[] heap, int i, int j) { Comparable temp = heap[i]; heap[i] = heap[j]; heap[j] = temp; } private static void sink (Comparable[] heap, int target, int range) { while (2 *target<=range){ int max; if (2 *target+1 <range){ if (less(heap,2 *target,2 *target+1 )){ max = 2 *target+1 ; }else { max = 2 *target; } }else { max = 2 *target; } if (!less(heap,target,max)){ break ; } exch(heap,target,max); target = max; } } }