Java内存模型
Java内存模型
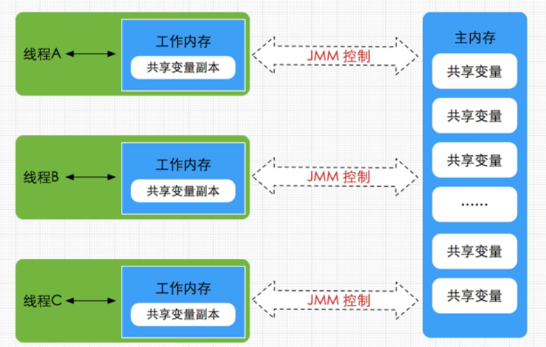
Java线程内存模型跟cpu缓存模型类似,是基于cpu缓存模型来建立的,Java线程内存模型是标准化的,屏蔽掉了底层不同计算机的区别
Java原子操作详解
- read(读取):从主内存读取数据
- load(载入):将主内存读取到的数据写入工作内存
- use(使用):从工作内存读取数据来计算
- assign(赋值):将计算好的值重新赋值到工作内存中
- store(存储):将工作内存数据写入主内存
- write(写入):将store过去的变量值赋值给主内存中的变量
- lock(锁定):将主内存变量加锁,标识为线程独占状态
- unlock(解锁):将主内存变量解锁,解锁后其他线程可以锁定该变量
情景:
线程一:拿到initFlag后,执行 while(!initFlag) 语句
线程二:拿到initFlag后,对其进行取反
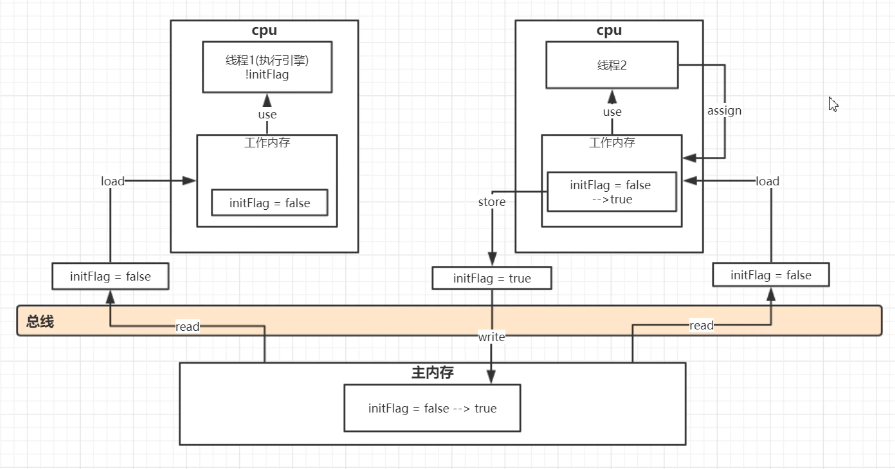
结果:线程一死循环,线程二修改了共享变量的值
volatile
解决上面的问题可以通过对共享变量加volatile关键字解决
volatile概述
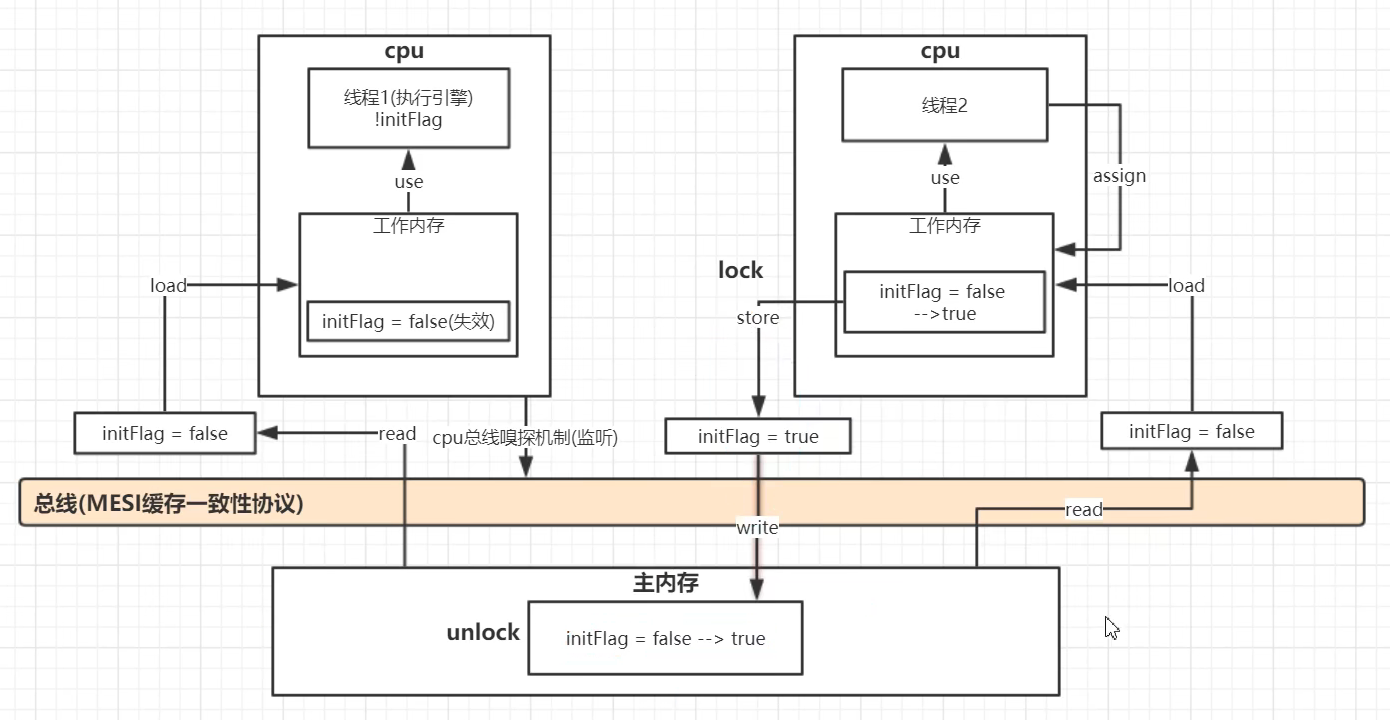
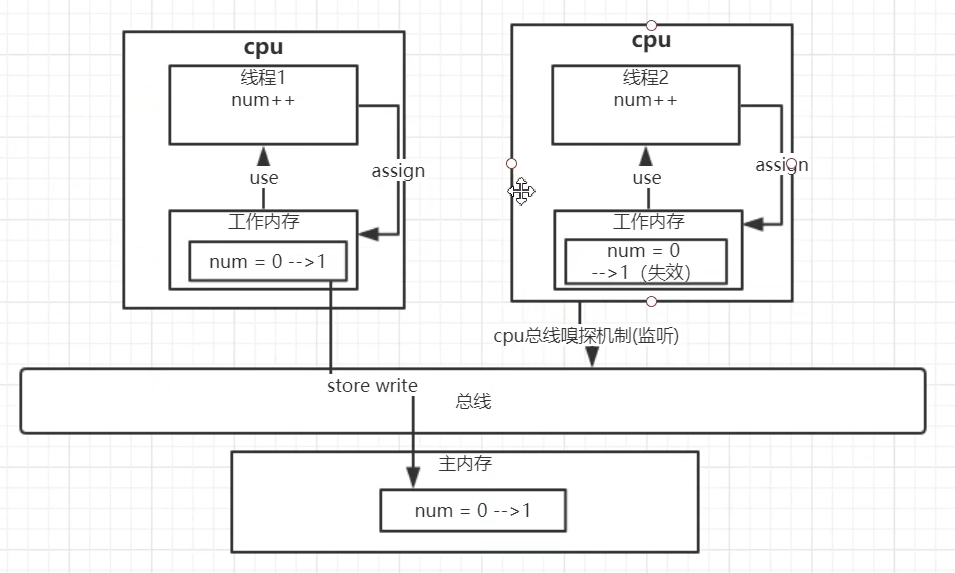
一个线程对volatile关键字修饰的共享变量副本进行修改后,会立马将修改后的值写入主内存中,其他的线程通过cpu总线嗅探机制监听到这个共享变量的值被修改过后,就会将自己线程工作内存中的共享变量副本失效掉,之后再使用的话就去主内存中取最新的值
volatile原理
底层实现主要是通过汇编lock前缀指令,它会锁定这块内存区域的缓存,并回写到主内存

Lock在具体的执行上,它先对总线和缓存加锁,然后执行后面的指令,在Lock锁住总线的时候,其他CPU的读写请求都会被阻塞,直到锁释放。最后释放锁后会把高速缓存中的脏数据全部刷新回主内存,且这个写回内存的操作会使在其他CPU里缓存了该地址的数据无效。
缓存行
缓存是分段(line)的,一个段对应一块存储空间,我们称之为缓存行,它是CPU缓存中可分配的最小存储单元,大小32字节、64字节、128字节不等,这与CPU架构有关,通常来说是64字节。当CPU看到一条读取内存的指令时,它会把内存地址传递给一级数据缓存,一级数据缓存会检查它是否有这个内存地址对应的缓存段,如果没有就把整个缓存段从内存(或更高一级的缓存)中加载进来。
一个问题:如果存在两个线程都修改了共享变量,都要向主内存中写入的情况如何?
volatile不能保证原子性
情景:
new出若干个线程,对volatile修饰的共享变量执行自增操作,结果并不能得到期望的值
原因:自增操作不是原子性的(先读取,再修改,最后写回工作内存)
A、B两个线程同时自增i。由于volatile可见性,因此步骤1两条线程一定拿到的是最新的i,也就是相同的i,但是从第2步开始就有问题了,有可能出现的场景是线程A自增了i并回写,但是线程B此时已经拿到了i,不会再去拿线程A回写的i,因此对原值进行了一次自增并回写,这就导致了线程非安全,也就是多线程技术器结果不对
如果线程A对i进行自增了以后cpu缓存不是应该通知其他缓存,并且重新load i么?
拿的前提是读,问题是,线程A对i进行了自增,线程B已经拿到了i并不存在需要再次读取i的场景,当然是不会重新load i这个值的。
ps:也就是线程B的缓存行内容的确会失效。但是此时线程B中i的值已经运行在加法指令中,不存在需要再次从缓存行读取i的场景。
内存屏障
查看如下代码,猜测a、b的值
1 | public class Test { |
你可能会觉得有三种结果
- a=1,b=0
- a=0,b=1
- a=0,b=0
但其实还有一种结果:a=1,b=1;这是为什么呢?
这是因为cpu为了优化代码的执行速度可能会进行指令重排的操作,例如:
1 | a = 1; |
这两条代码并没有产生依赖,他们的顺序并不影响代码执行,则可能重排成如下
1 | b = 2; |
这就是指令重排
而上述代码也可能存在指令重排,重排成如下代码
1 | //线程一 |
这是导致 a=1,b=1 的原因
什么样的指令可以重排序?
对cpu来说,基本上任何指令都可以实现重排序,因为这样可以提高性能,除了一些lock或禁止重排序的指令外。
对jvm来说,jvm规范中提到了happens-before原则,也就是不在下面8条原则中的指令都可以重排序:
- 程序次序原则:在一个线程内,代码按照编写时的次序执行(jvm会对指令重排序,但是会保证最终一致性)。
- 锁定原则:如果一个锁是锁定状态,要先unlock后才能lock。
- volatile变量规则:对变量的写操作要先于对变量的读操作。
- 传递规则:A先于B,B先于C,那么A先于C。
- 线程启动规则:线程的start()方法先于run()方法运行。
- 线程中断规则:线程收到了中断信号,那么之前一定有interrupt()。
- 线程终结规则:线程的任务执行单元要发生在线程死亡之前。
- 对象的终结规则:线程的初始化先于finalize()方法之前。
解决:增加volatile关键字
1 | public static volatile int x = 0, y = 0; |
被volatile修饰的变量在编译成字节码文件时会多个lock指令,该指令在执行过程中会生成相应的内存屏障,以此来解决可见性跟重排序的问题。
内存屏障的作用:
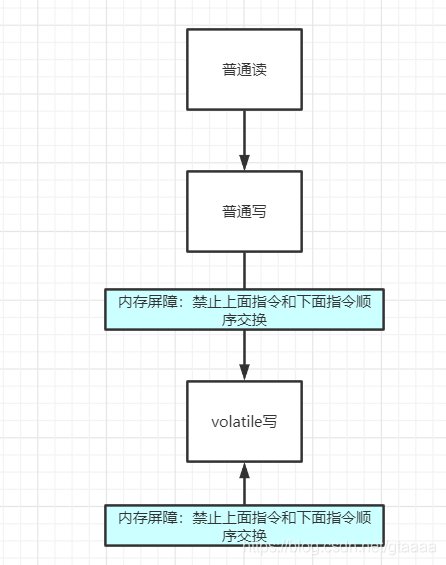
- 在有内存屏障的地方,会禁止指令重排序,即屏障下面的代码不能跟屏障上面的代码交换执行顺序。
- 在有内存屏障的地方,线程修改完共享变量以后会马上把该变量从本地内存写回到主内存,并且让其他线程本地内存中该变量副本失效(使用MESI协议)
内存屏障是CPU指令。如果你的字段是volatile,Java内存模型将在写操作后插入一个写屏障指令,在读操作前插入一个读屏障指令。
下面是基于保守策略的JMM内存屏障插入策略:
在每个volatile写操作的前面插入一个StoreStore屏障。
在每个volatile写操作的后面插入一个StoreLoad屏障。
在每个volatile读操作的前面插入一个LoadLoad屏障。
在每个volatile读操作的后面插入一个LoadStore屏障。